Przepływ wykonany zostanie z wykorzystaniem dodatkowych procesorów jak np. ConvertExcelToCSVProcessor czy PutDatabaseRecord oraz wsadowego FlowFile z danymi w formacie JSON z parametrami połączenia do serwera SFTP i informacją, które pliki Excel należy zaimportować do bazy danych MySQL. Pracę nad przepływem będą sukcesywnie zapisywane na poszczególnych etapach pracy do Apache NiFi Registry.
Podgląd danych z plików XLSX
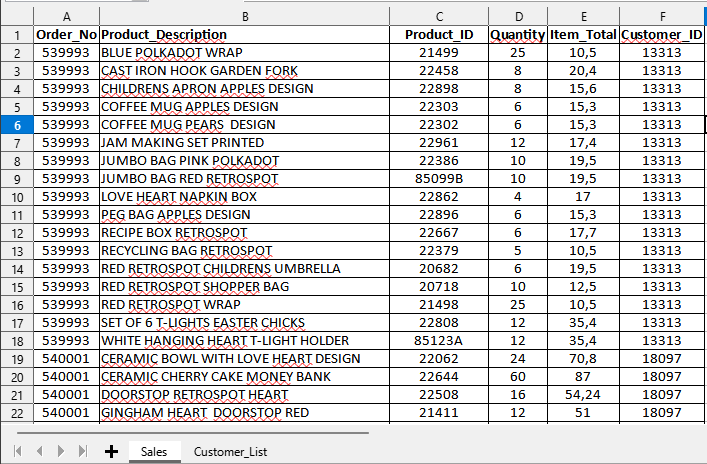
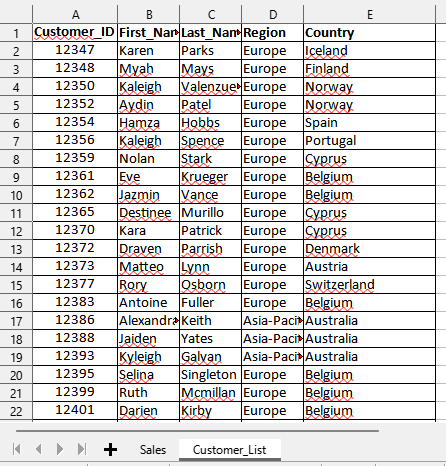
Poniżej przedstawiam przykładowy plik Excel, który zawiera w sobie dwa arkusze z danymi sprzedażowymi oraz z listą kontrahentów. Całość została podzielona na dwa pliki, które zostaną zaimportowane do MySQL.
Konstrukcja przepływu danych
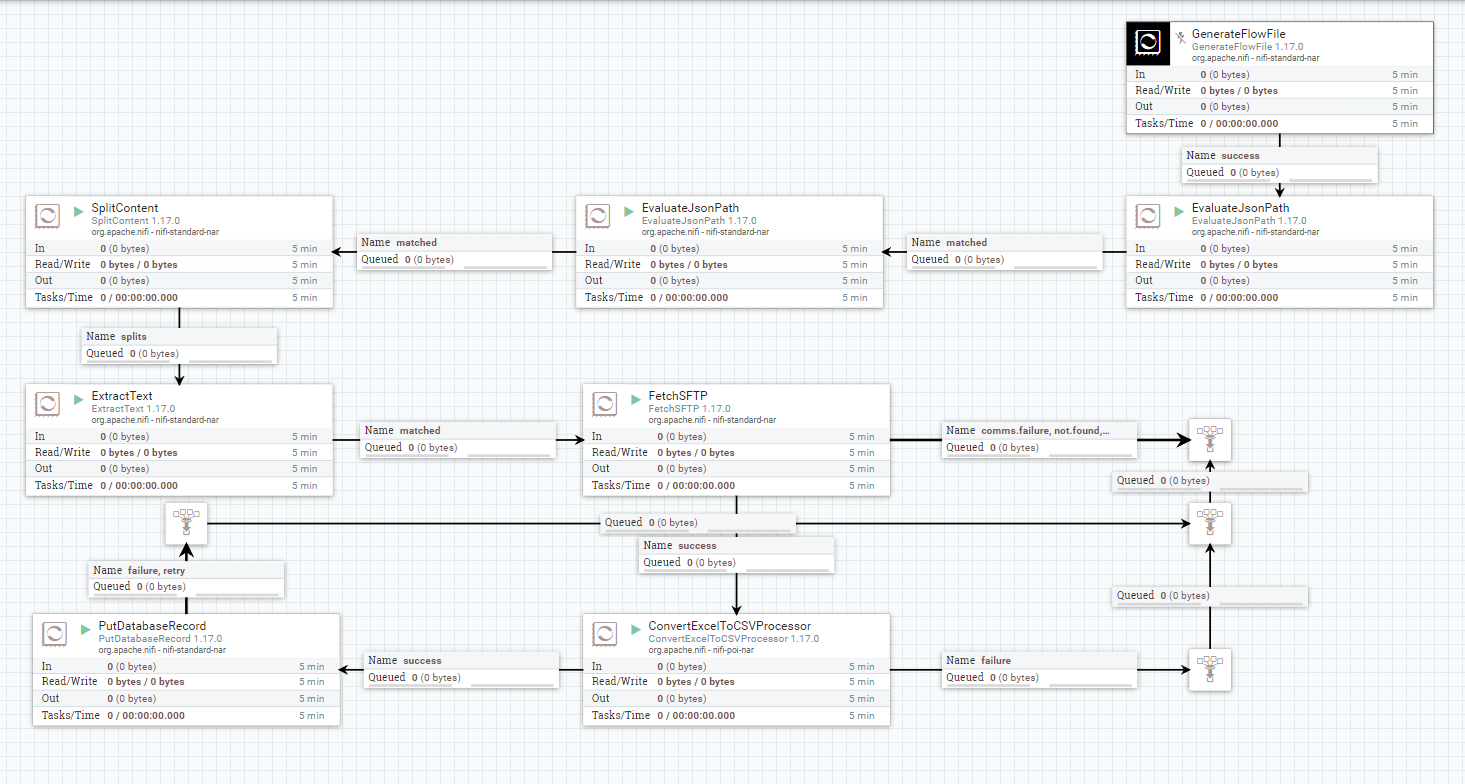
Początek przepływu został zaczerpnięty po części z poprzedniego artykułu Proste scalanie plików CSV pobranych z SFTP, czyli operować będziemy na informacjach jakie dostarczy nam wsadowy FlowFile z danymi w formacie JSON. Informacje w wygenerowanym FlowFile z JSON zostaną odpowiednio wyodrębnione i zapisane w postaci atrybutów za pomocą procesorów EvaluateJsonPath. Kolejne procesory SplitContent / ExtractText podzielą listę z plikami Excel do zaimportowania, przez co otrzymamy FF z nazwą dla każdego pliku, który chcemy przeprocesować. Dane z JSON pozwolą nam na połączenie i pobranie plików Excel z serwera SFTP przy wykorzystaniu procesora FetchSFTP. Posiadając już pliki xlsx z danymi, użyjemy procesora ConvertExcelToCSVProcessor, który wyodrębni każdy arkusz do osobnego FlowFile. Otrzymane dane w FF zaimportujemy przy użyciu procesora PutDatabaseRecord do serwera MySQL.
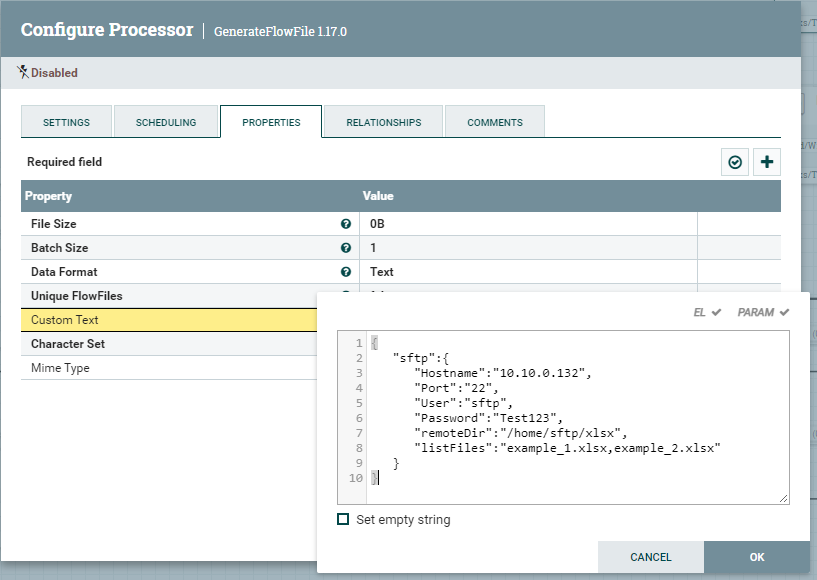
GenerateFlowFile z danymi w formacie JSON
We właściwościach procesora w atrybucie Custom Text umieszczamy, poniższe dane.
{
"sftp":{
"Hostname":"10.10.0.132",
"Port":"22",
"User":"sftp",
"Password":"Test123",
"remoteDir":"/home/sftp/xlsx",
"listFiles":"example_1.xlsx,example_2.xlsx"
}
}
EvaluateJsonPath
Pierwszy procesor jest odpowiedzialny za wyodrębnienie wszelkich informacji zawartych w JSON, a następnie zapisze w atrybutach FlowFile.
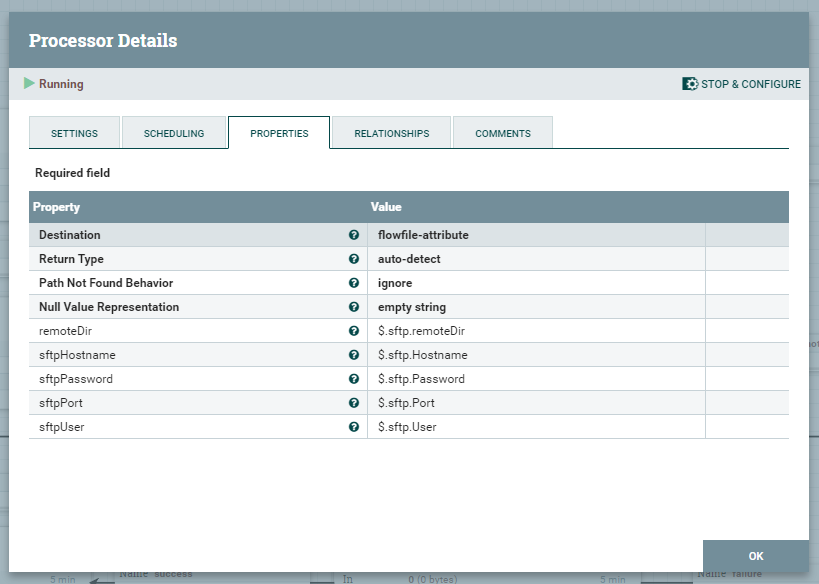
Kolejny, wyodrębni zawartość listFiles do zawartości FlowFile co pozwoli nam na podzielenie FF na osobne pliki, które potrzebne są do dalszego procesowania.
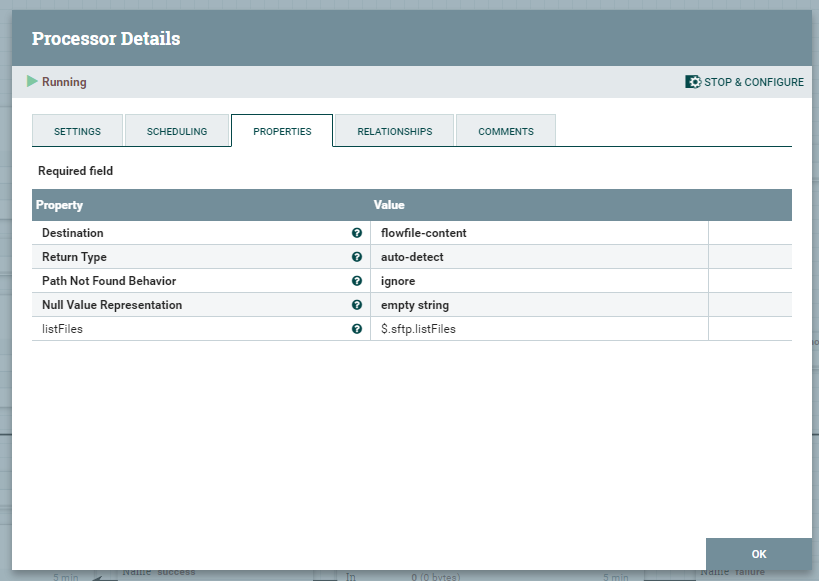
SplitContent / ExtractText
Kolejne procesory podzielą pierwotny FlowFile i utworzą osobne FF dla każdego pliku xlsx wraz z ich oryginalnymi nazwami. Parametr Byte Sequence wskazuje na seperator, po którym zostanie podzielona lista.
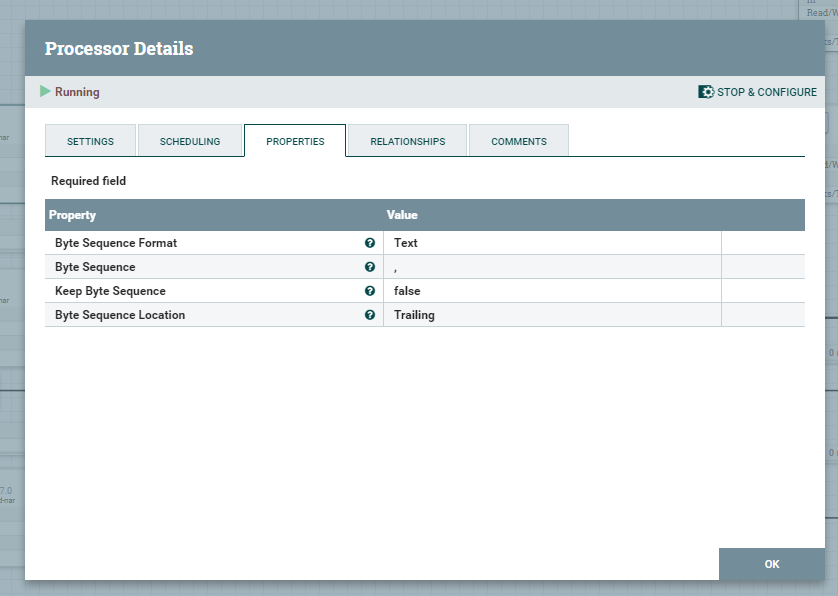
FetchSFTP
Konfiguracja procesora oparta jest o parametry, które wcześniej zostały wyodrębnione z wejściowego FlowFile zawierającego dane w formacie JSON. Atrybut ${sftpPassword}, należy uzupełnić we właściwości Password procesora.
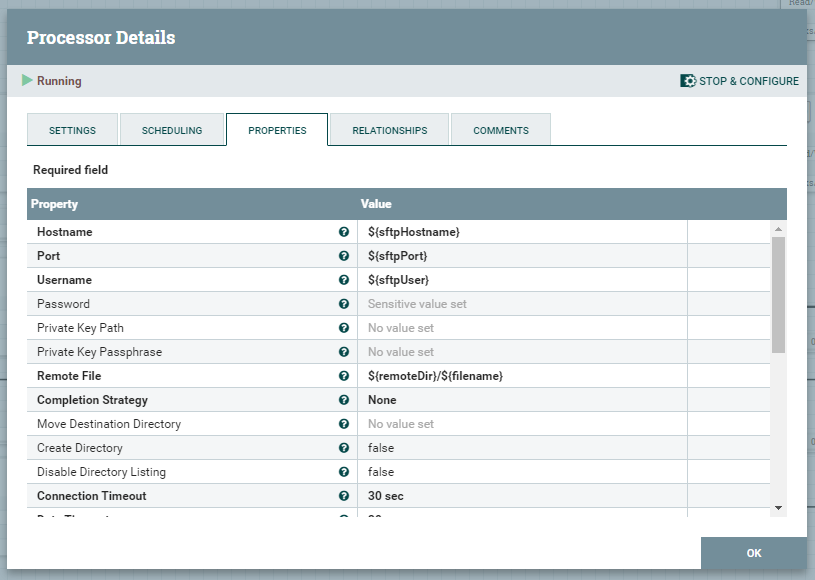
ConvertExcelToCSVProcessor
Wskazane, poniżej ustawienia procesora ConvertExcelToCSVProcessor pozwolą na poprawne wyodrębnienie arkuszy z plików Excel do osobnych FlowFile, co pozwoli w kolejnym etapie na rozróżnienie, które arkusze mają zostać załadowane do poszczególnych tabel.
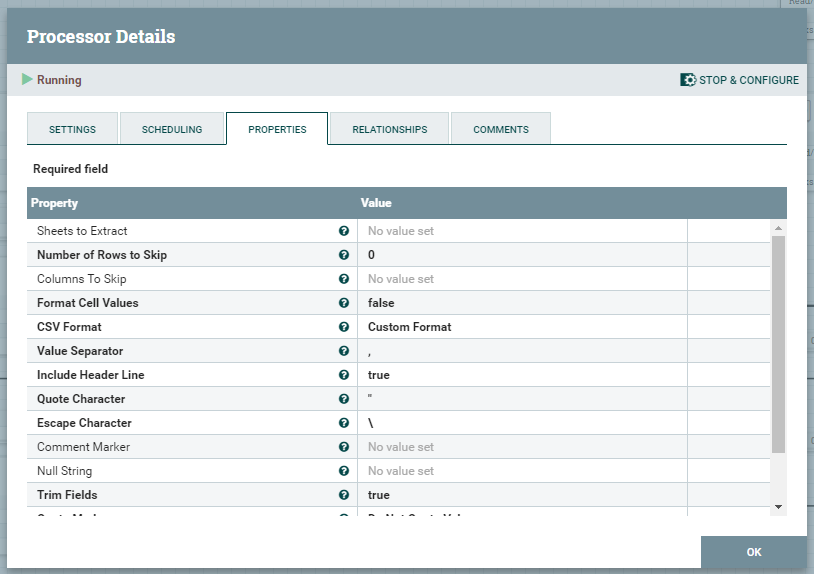
PutDatabaseRecord
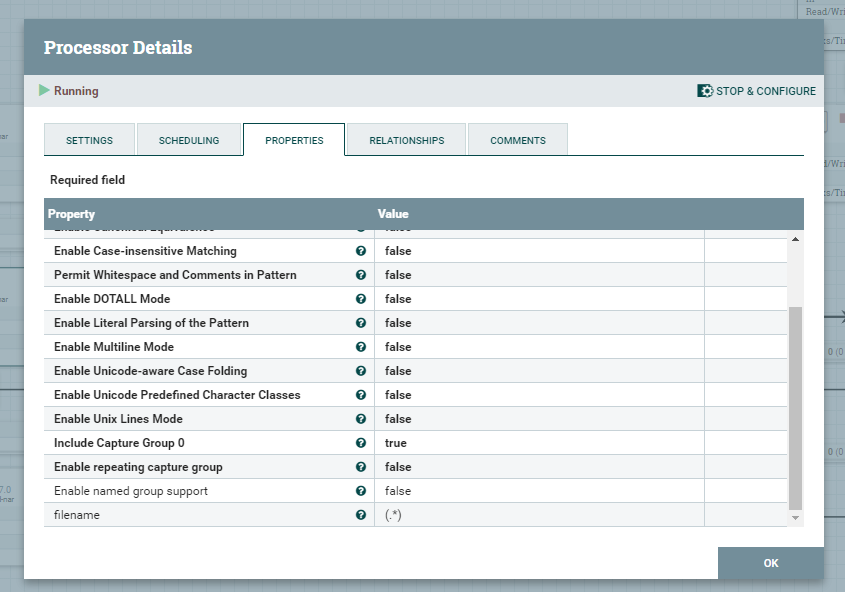
Oprócz konfiguracji tego procesora, niezbędne jest wykonanie dodatkowych akcji w postaci utworzenia CSVReader oraz DBCPConnectionPool. Table Name, jak można zauważyć na poniższym zrzucie budowana jest wyrażeniem regularnym, na podstawie nazwy FlowFile.
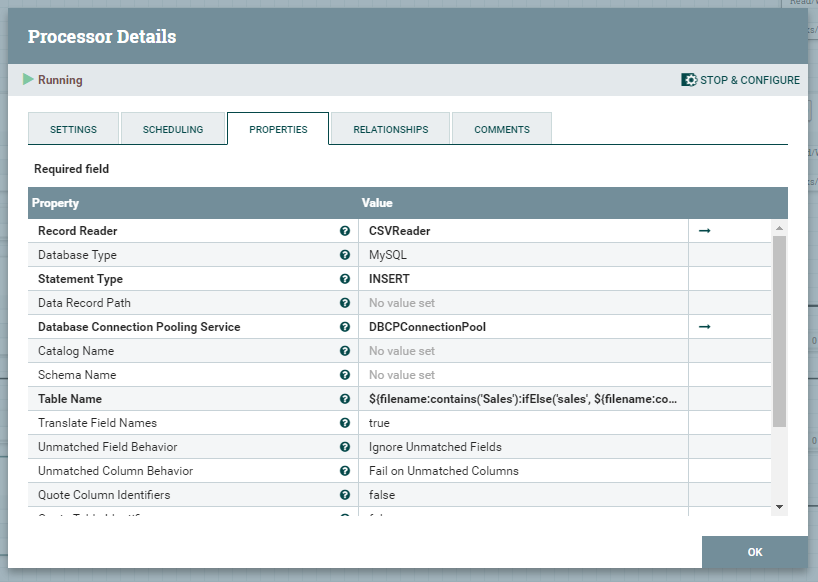
Wyrażenie regularne użyte do zbudowania nazwy tabeli docelowej, do której będą importowane dane działa w oparciu o nazwę FlowFile. Arkusze z nazwą Customer_List będą ładowane do tabeli customer, a dane sprzedażowe z arkusza Sales do tabeli sales.
${filename:contains('Sales'):ifElse('sales', ${filename:contains('Customer_List'):ifElse('customer',${filename})})}Record Reader
W pierwszej kolejność przechodzimy na pole Record Reader i lewym przyciskiem z menu wybieramy Create new service. Z listy dostępnym kontrolerów, należy wybrać CSVReader, a następnie Create.
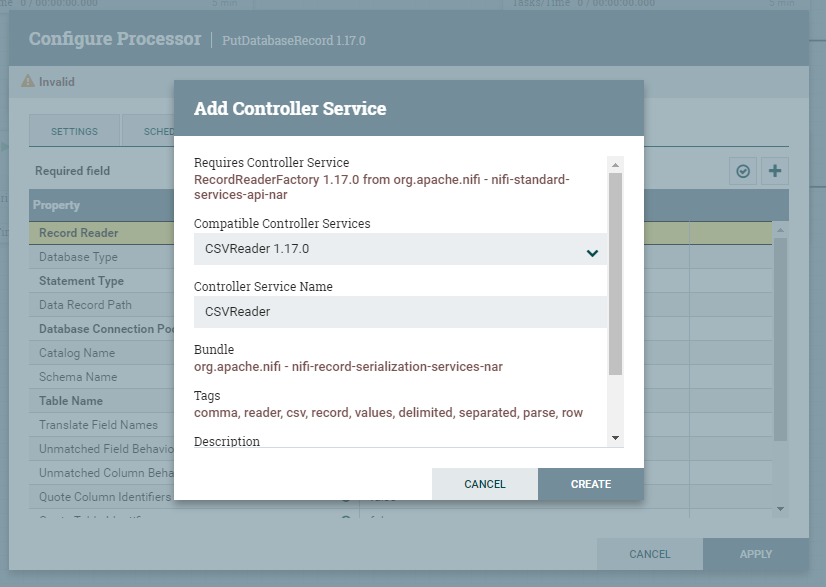
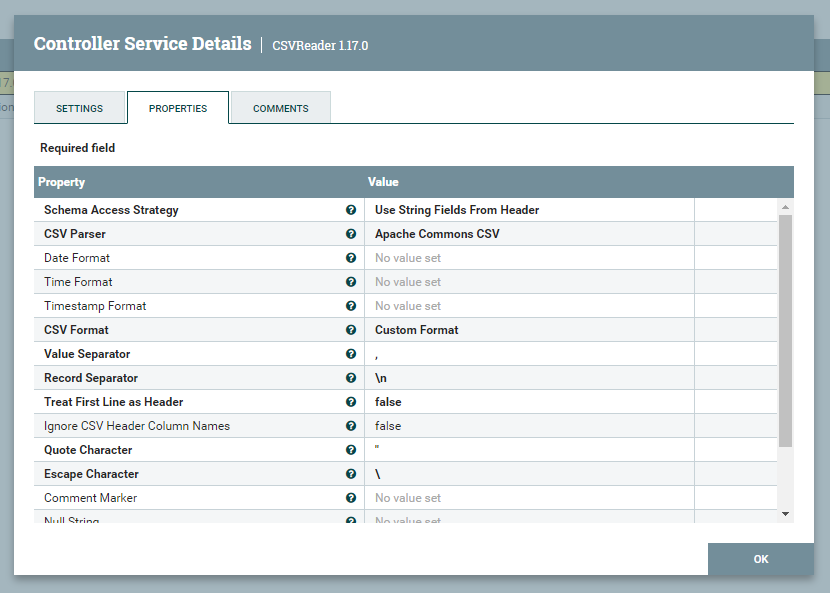
Przechodzimy do ustawień utworzonego wcześniej kontrolera i konfigurujemy jego parametry zgodnie z załączonym zrzutem. Ważne jest, aby właściwość Schema Access Strategy został ustawiony na Use String Fields From Header.
DBCPConnectionPool
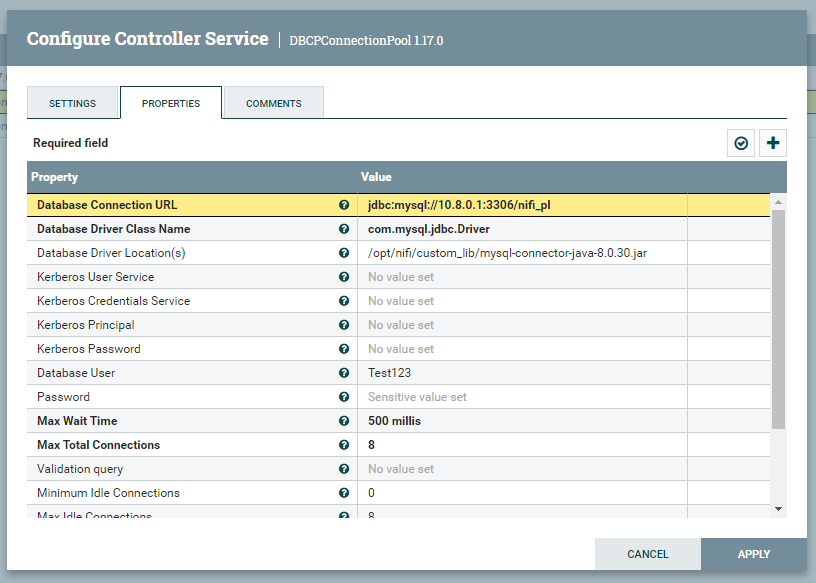
Zanim przejdziemy do konfigurowania kontrolera DBCPConnectionPool, należy pobrać wcześniej prawidłowy konektor bazy danych, który pozwoli na podłączenie się do serwera bazodanowego MySQL. W moim przypadku jest to MySQL Connector/J 8.0.30, pobiorę go do wcześniej utworzonego katalogu custom_lib w /opt/nifi.
sudo wget https://repo1.maven.org/maven2/mysql/mysql-connector-java/8.0.30/mysql-connector-java-8.0.30.jar -P /opt/nifi/custom_libAnalogicznie do poprzednich kroków, należy utworzyć kontroler, który posłuży do połączenia się z bazą danych. Klikamy zatem we właściwości Database Connection Pooling Service, wybieramy Create new service i domyślnie pojawi się DBCPConnectionPool. Uzupełniamy właściwości kontrolera, jak poniżej ze wskazaniem własnego serwera i bazy danych, do której chcecie się połączyć.
Podsumowanie
Wszystkie wymagane procesory zostały przez Nas odpowiednio skonfigurowane, a więc nie pozostaje nic innego jak ich należyte połączenie odpowiednimi kolejkami, jak na poniższym zrzucie ekranu.