Do wykonania przepływu wykorzystamy FlowFile z danymi w formacie JSON zawierający parametry połączenia do serwera SFTP oraz informację, które pliki należy ze sobą scalić. Standardowo jak na dobrych specjalistów przystało przepływ zostanie umieszczony w Apache NiFi Registry, a jak wykonać te podstawowe kroki, aby rozpocząć pracę odnajdziecie w artykule Budowa prostego i automatycznego przepływu danych.
Podgląd danych z plików CSV
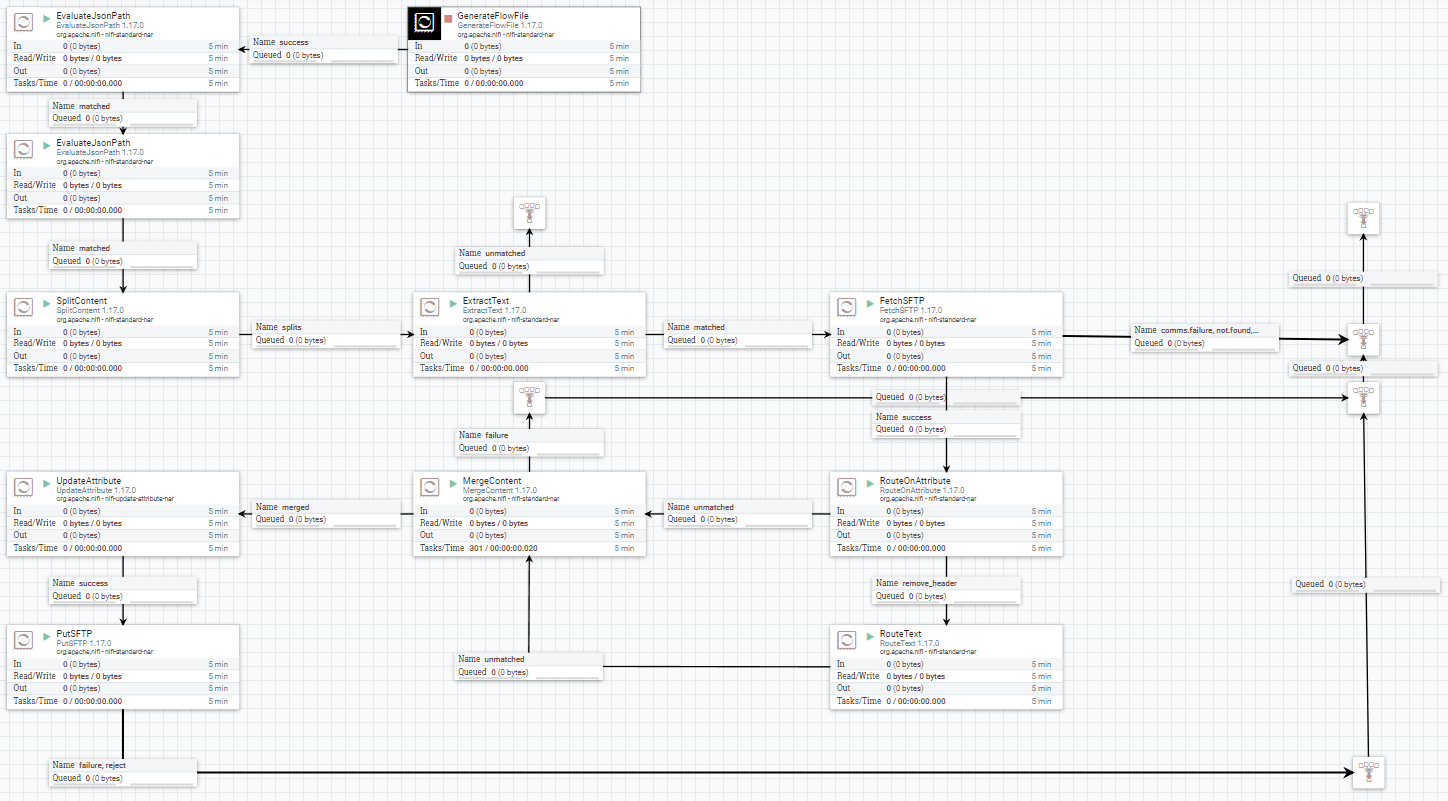
Konstrukcja przepływu danych
Przepływ opiera się głównie na wsadzie z danymi w formacie JSON, który zawiera informację na temat serwera SFTP i potrzebnych plików CSV do połączenia. W pierwszej kolejności flow za pomocą procesora EvaluateJsonPath pobierze i zapisze potrzebne dane do atrybutów FlowFile. Wyodrębnione lista plików umożliwi rozdzielenie przy pomocy SplitContent na osobne FlowFile. Z zawartości każdego FlowFile wyekstraktujemy nazwy plików dzięki procesorowi ExtractText i zapiszemy w nazwie wcześniej stworzonego FF. Posiadając niezbędne dane odnośnie plików i serwera SFTP, użyjemy procesora FetchSFTP, który pobierze nam pliki CSV do zawartości FlowFile. Z racji tego, że dane w pliku CSV zawierają wiersz z nagłówkiem, musimy odpowiednio przygotować dane przed ich scaleniem poprzez usunięcie nagłówka z drugiego i trzeciego FlowFile, a pozostawiając go w pierwszym, w tym celu posłużą nam procesory RouteOnAttribute i RouteText. Przygotowane w ten sposób FlowFile łączymy procesorem MergeContent, a następnie zmienimy jego nazwę tak, aby zawierała ilość scalonych plików oraz datę przetworzenia. W ostatnim etapie zapisujemy gotowy plik z powrotem na serwerze SFTP.
GenerateFlowFile z danymi w formacie JSON
Procesor będziemy wyzwalać ręcznie przy pomocy opcji Run Once, który znajdzie klikając prawy przycisk myszy na procesorze.
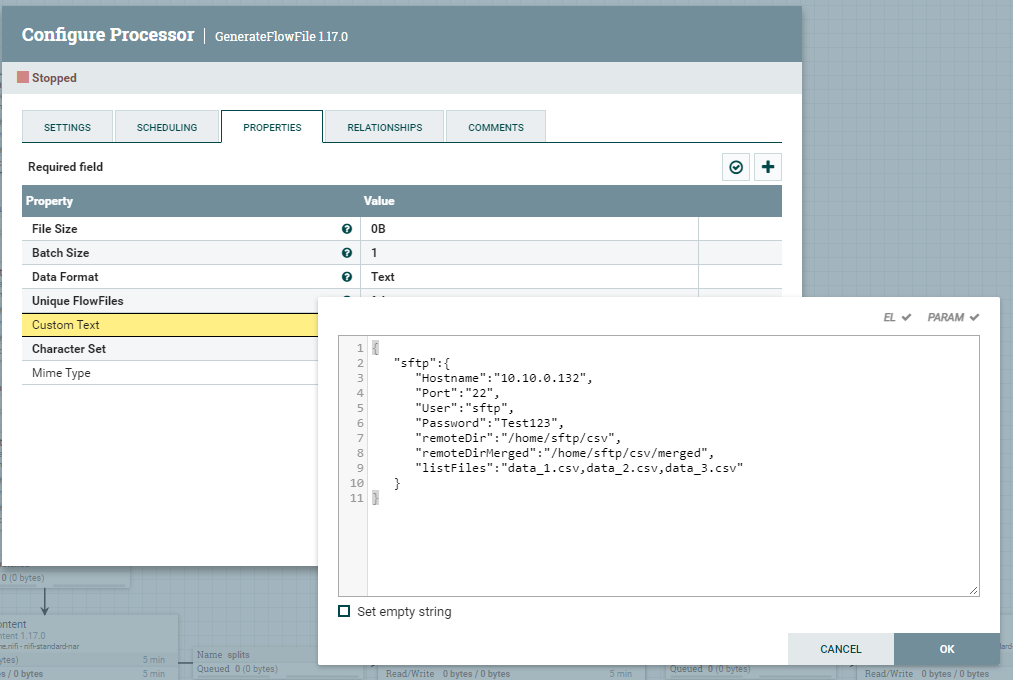
W atrybucie Custom Text znajdujący się we właściwościach procesora umieszczamy, poniższe dane.
{
"sftp":{
"Hostname":"10.10.0.132",
"Port":"22",
"User":"sftp",
"Password":"Test123",
"remoteDir":"/home/sftp/csv",
"remoteDirMerged":"/home/sftp/csv/merged",
"listFiles":"data_1.csv,data_2.csv,data_3.csv"
}
}
EvaluateJsonPath
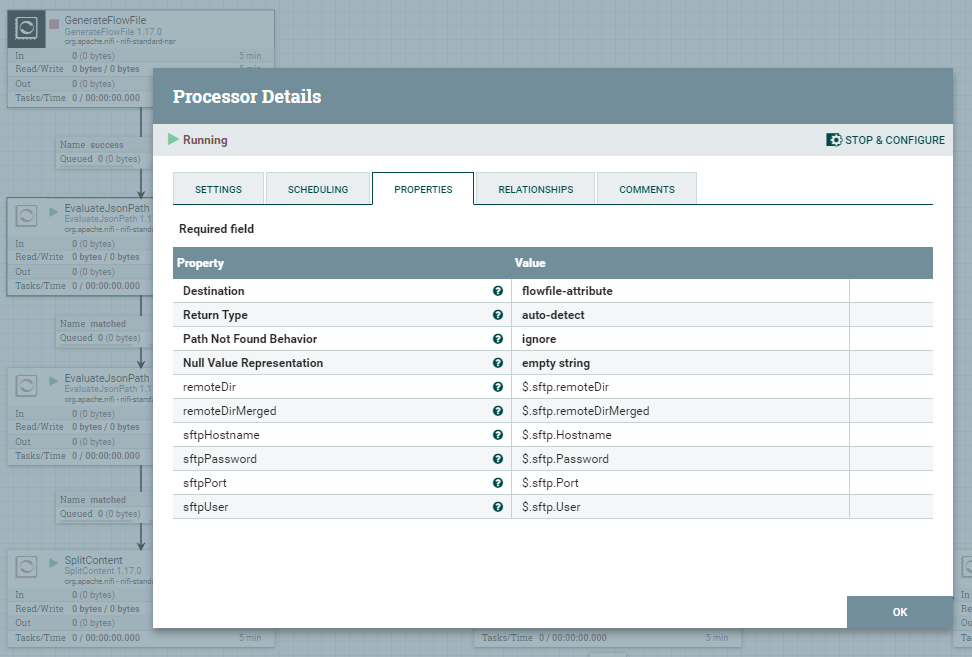
W kolejnej części skonfigurujemy dwa procesory EvaluateJsonPath, pierwszy z nich zapisze dane z JSON do atrybutów FlowFile. Drugi procesor będzie odpowiedzialny za zapisanie atrybutu listFiles do zawartości FlowFile.
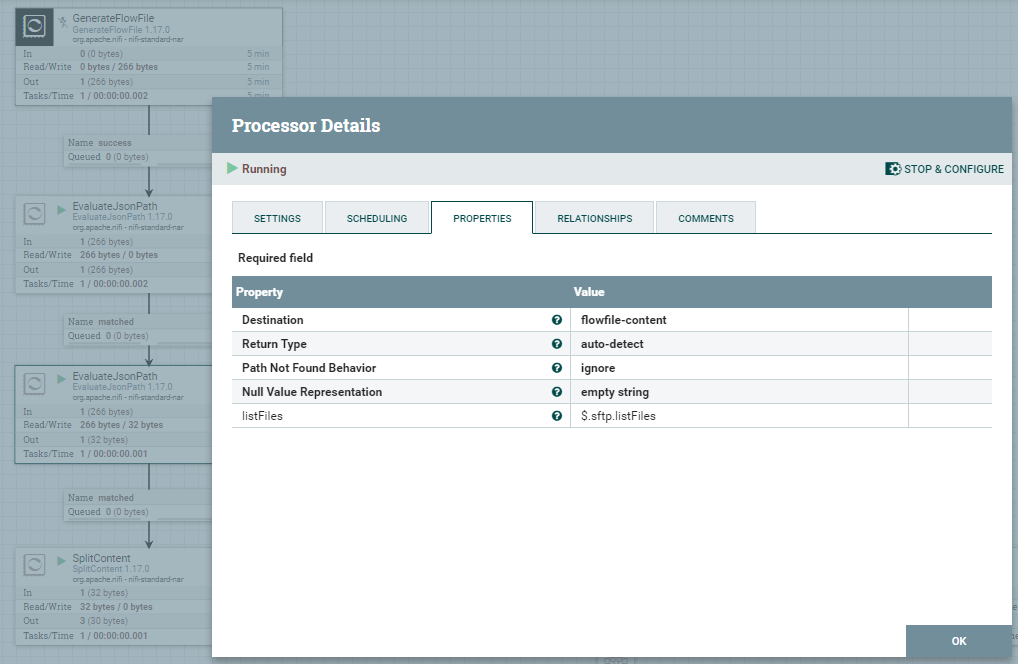
SplitContent / ExtractText
W tym kroku rozdzielimy FlowFile na trzy osobne, które pozwolą nam na przeprowadzanie kolejnych operacji i pobraniu potrzebnych plików z serwera SFTP. Właściwość Byte Sequence wskazuje na separator, który został użyty w listFiles do przekazania listy plików, a który posłuży nam do rozdzielenia FF.
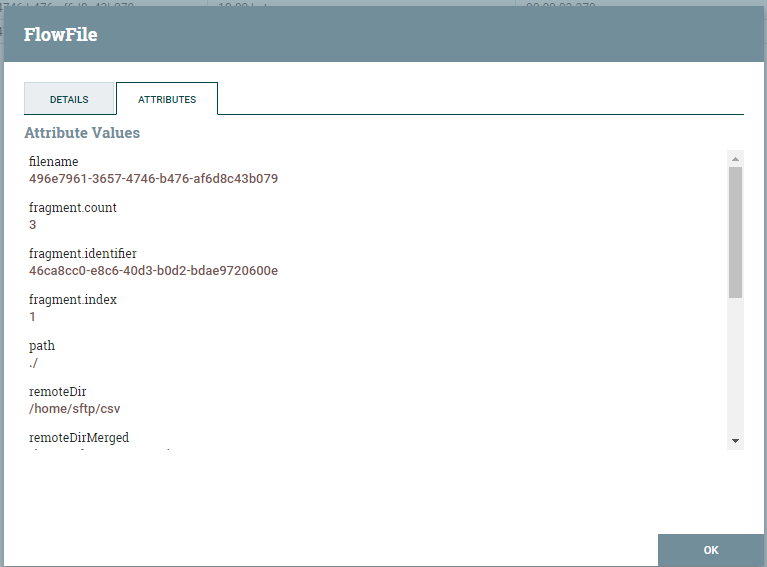
Po rozdzieleniu FlowFile uzyskujemy bardzo ważne informacje w postaci atrybutów fragment.count, który określa ile plików powstało z FlowFile, fragment.identifier pozwalający na rozróżnienie wspólnych FlowFile oraz fragment.index, określający kolejność elementów. W późniejszym etapie atrybuty te zostaną wykorzystane do określenia, który plik nie jest pierwszy oraz umożliwi scalenie tych plików.
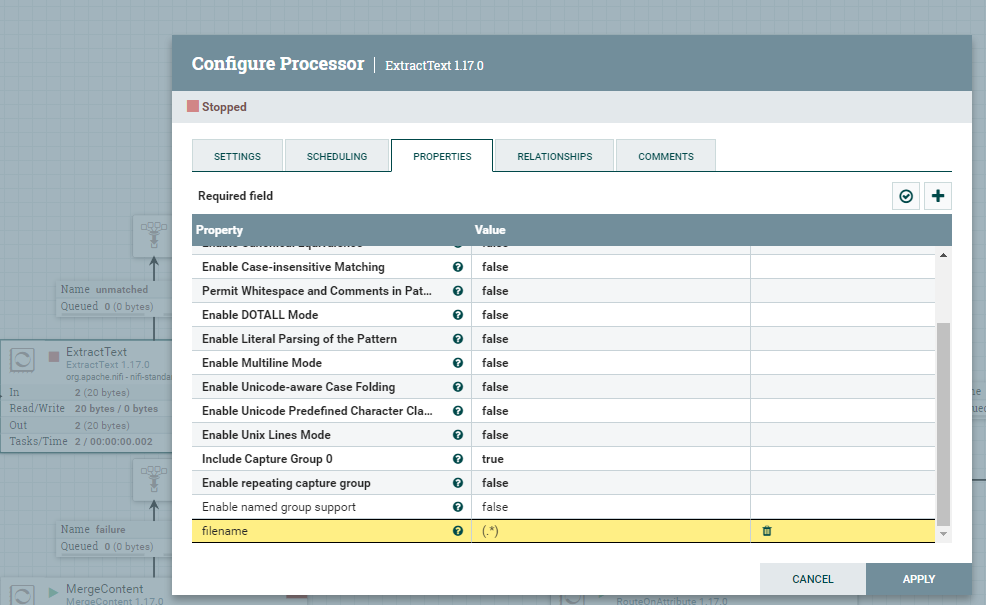
Dodatkowo, aby w łatwiejszy sposób przeszukiwać kolejki w Apache NiFi zmienimy nazwę FlowFile na nazwy plików CSV. W tym celu, należy użyć procesora ExtractText z następującą konfiguracją.
FetchSFTP / PutSFTP
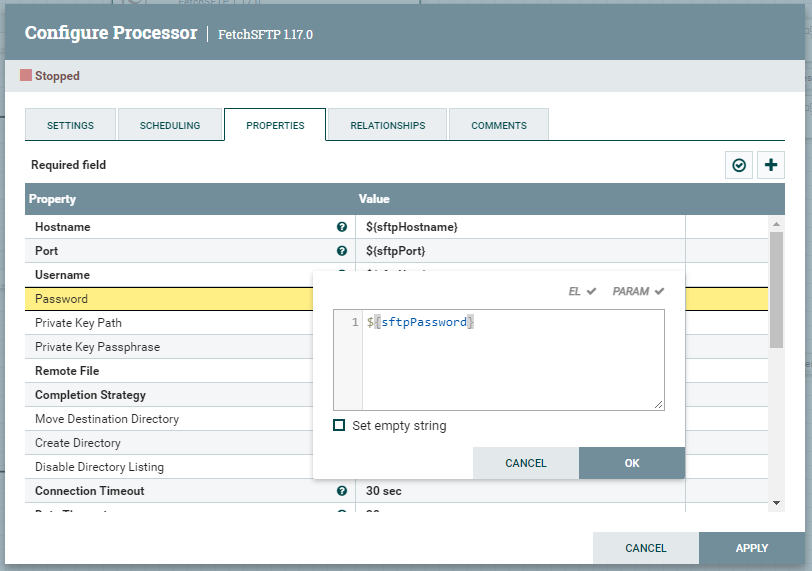
Procesor FetchSFTP służy do pobierania danych z serwera, a odwrotną rolę, czyli zapisywanie pełni PutSFTP. Do konfiguracji procesorów wykorzystamy wcześniej przygotowane atrybuty. Ważne jest, aby w obu przypadkach uzupełnić właściwość Password atrybutem ${sftpPassword}. Jest to na tyle istotne, że ta właściwość zostanie zapisana jako wartość Sensitive value set i będzie ukryta.
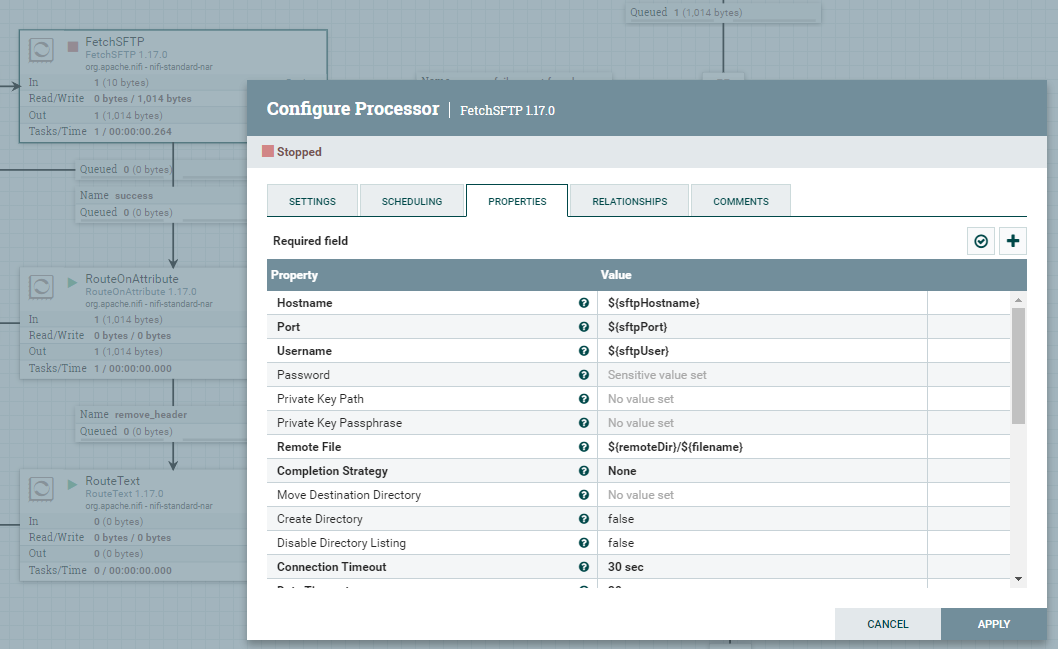
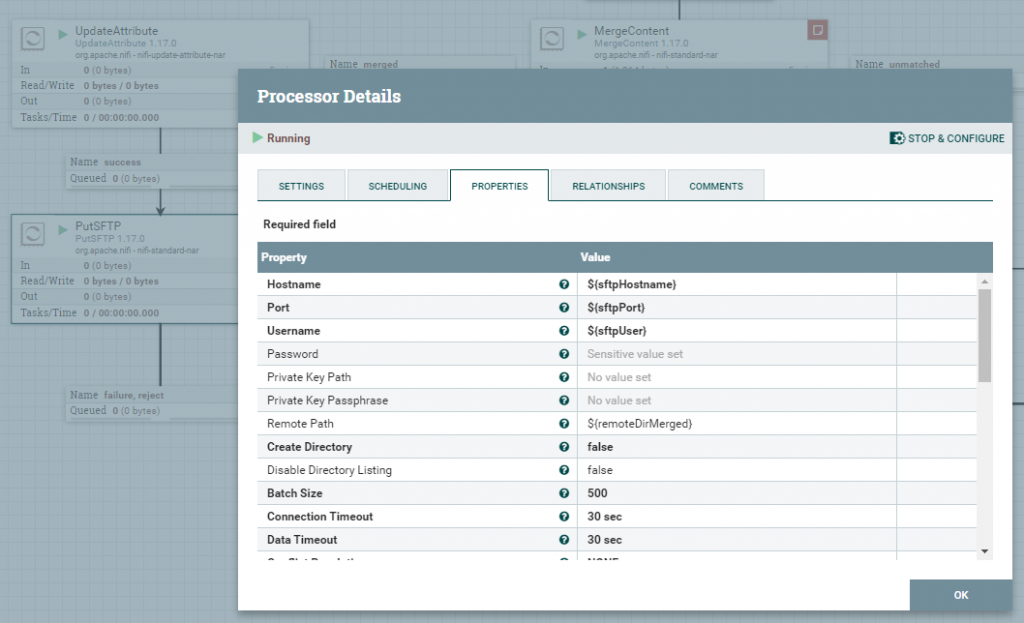
RouteOnAttribute / RouteText
Gdy już mamy pobrane dane z serwera SFTP musimy je w pewien sposób przetransformować, aby zachować poprawność danych. Przed scaleniem, należy usunąć zbędne wiersze z nagłówkami z dwóch FlowFile. Procesor RouteOnAttribute wykorzysta atrybut fragment.index w celu rozróżnienia, który FlowFile nie jest pierwszym i skieruje je do odpowiedniej kolejki.
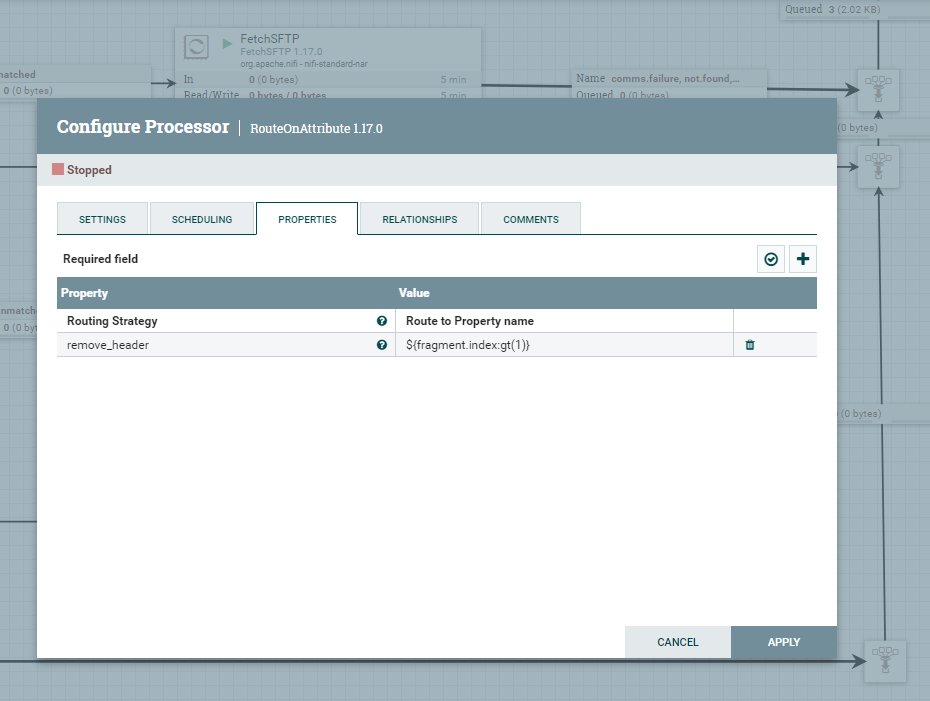
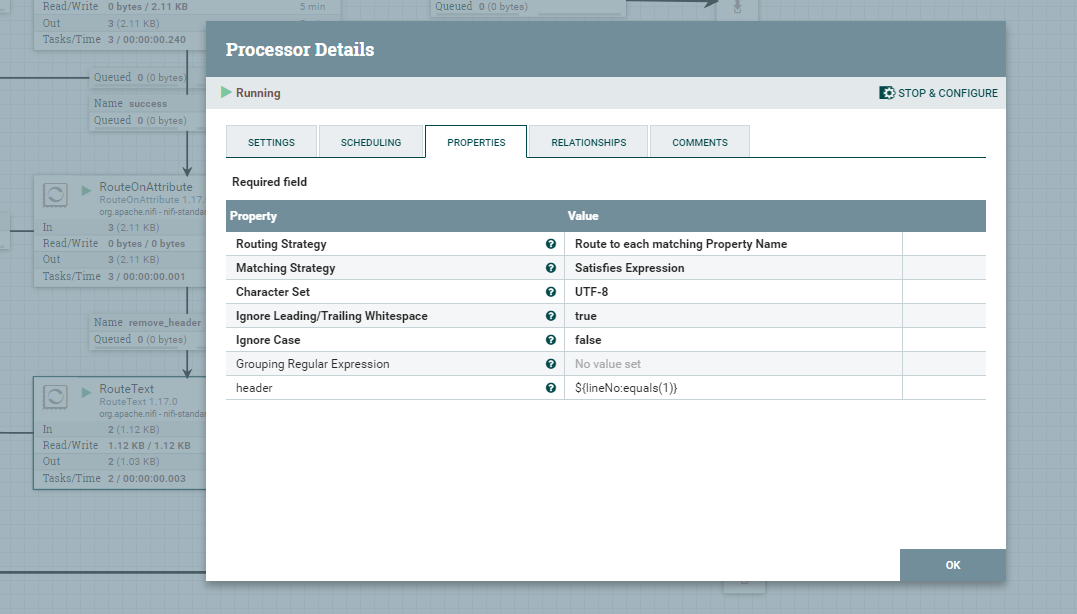
Wcześniej wspomnianą kolejkę remove_header kierujemy do procesora RouteText, który umożliwi usunięcie pierwszego wiersza, który zawiera nagłówki kolumn.
MergeContent
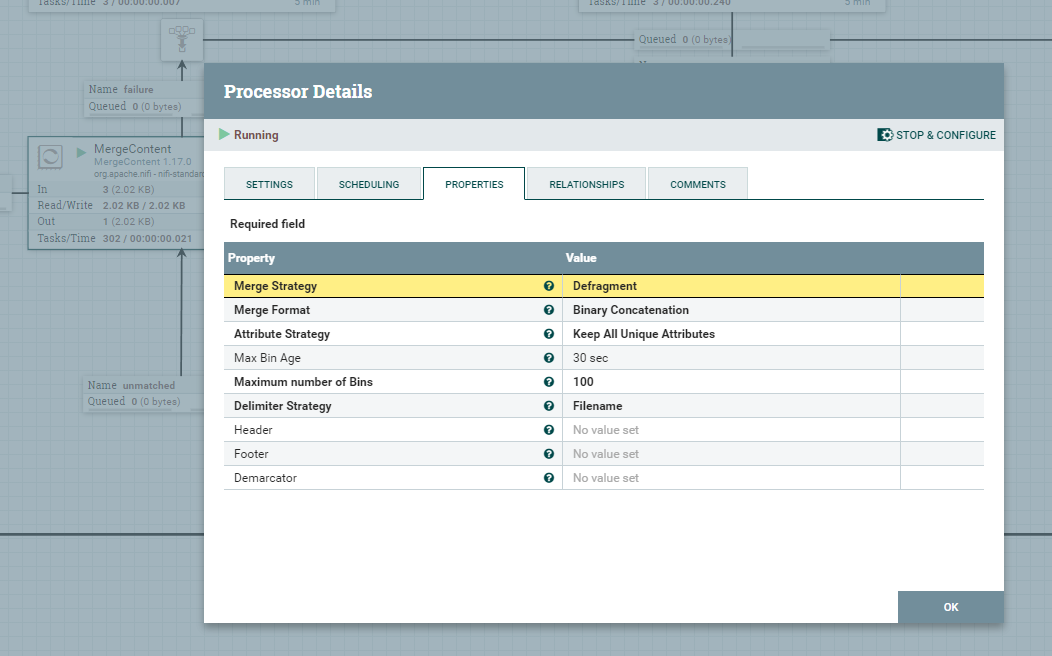
Przy pomocy procesora MergeContent scalimy wcześniej przetransformowane FlowFile. Ważne jest, aby wykorzystać Defragment w właściwości Merge Strategy, ta strategia opiera się o wcześniej utworzone atrybuty fragment.count, fragment.identifier, fragment.index, które zapewnią integralność i spójność scalonych plików.
UpdateAttribute
Przed wysłaniem scalanego pliku z powrotem na serwer SFTP, należy zmienić jego nazwę na bardziej przyjazną dla użytkownika, w tym celu wykorzystamy procesor UpdateAttribute z poniższym wyrażeniem NiFi.
merged_${fragment.count}_csv_${now():format("yyyy-MM-dd'_'HH:mm","GMT")}.csv Podsumowanie
Wszystkie potrzebne procesory zostały przez Nas odpowiednio przygotowane, a więc ostatnim etapem jest ich należyte połączenie odpowiednimi kolejkami, jak przedstawia poniższy zrzut ekranu.